Hadoop Distributed File System
官方文档:HDFS
HDFS是一个分布式文件系统,具有高容错的特点,它可以部署在“廉价”的通用硬件上,提供高吞吐率的数据访问,适合那些需要处理海量数据集的应用程序。
HDFS 集群状态预览:http://master:50070/dfshealth.html
HDFS 文件系统命令:FileSystemShell
这里只展开基础的几个组件 NameNode、DataNode 和 Secondary NameNode
NameNode
负责构建命名空间,管理文件的元数据,存在单点故障,具体可以参见高可用解决方案:
HDFSHighAvailabilityWithQJM
HDFSHighAvailabilityWithNFS
DataNode
数据节点负责读/写 Block ,定期向 Namenode 汇报自己节点上所存储的 Block 相关信息。
默认 Block 大小为 128MB,有 3 个复制集作为冗余备份,HDFS 会尽量将同一个文件的 Blocks 分散到不同的 DataNode 中,保证数据的高可用性;
Secondary NameNode
检查节点负责定期获取 NameNode edit logs 合并至元数据映像文件(fsimage),并将 fsimage 同步至 NameNode
读/写流程
客户端模式
读操作:
- 客户端访问 Namenode 获取文件的元数据(返回文件 Blocks 对应的 DataNode);
- 客户端就近随机选择连接 DataNode;
- DataNode 发送数据,客户端校验、接收完毕合成完整文件。
写操作:
- 客户端访问 NameNode 确认集群状态,确认目录是否可写;
- 客户端分割文件成多个 packets(以队列的形式管理);
- 客户端向 NameNode 申请数据存储请求以及复制集的存储节点;
- NameNode 返回分配好的 DataNode 节点;
- 客户端以 Pipeline 的形式向 DataNode 列表写入数据;
- 当 packets 都被确认写入成功时,客户端向 NameNode 报告写入完毕;
- NameNode 同步数据元数据;

集群:
YARN
官方文档:YARN
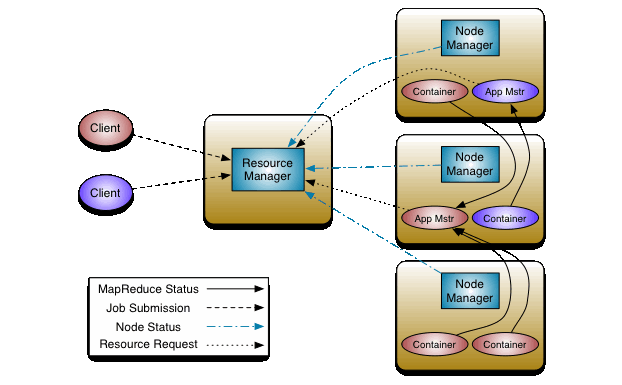
YARN是Hadoop集群的资源管理系统
Resource Manager
负责整个集群的资源管理及分配
NodeManager
NM 是每个节点上的资源和任务管理器。一方面,它定时地向 RM 汇报本节点的资源使用情况和 Container 运行状态;另一方面,它接受并处理来自 AM 的 Container 启动/停止等请求;
Application Master
负责单个应用的资源管理
MapReduce
官方文档:MR-Tutorial
分布式计算框架,重点有 Map(映射)、Shuffle(那啥)和 Reduce(化简)三个概念,其中,map 和 reduce 处理函数由用户定义,Shuffle过程由框架自动完成;
MR 过程:
Map 读取数据文件,split 输出
Partition/Sort/Combine/Copy/Merge 统称 Shuffle
Reduce 处理数据,输出结果
WrodCount 例子
1 | cat word0* |
Mapper
1 | # encoding: utf8 |
Reducer
1 | # encoding: utf8 |
运行
查看提交的应用程序 http://master:8088/cluster/apps/
1 | # -file 提交文件让 Hadoop 分发至各节点 (推荐使用: -files) |
参考
http://hadoop.apache.org/docs/stable/
https://www.ibm.com/developerworks/cn/web/wa-introhdfs/index.html
https://www.ibm.com/developerworks/cn/data/library/bd-yarn-intro/
Hadoop YARN 介绍